The goal of this project is to put together several things you have learned this semester to make an integrated application; most importantly, you will apply multi-threaded programming to a GUI application.
In this project, you will write a web-browser. It won't be full-featured, but it will have one interesting feature: It will display text in two panes (like a book), controlled by a single scroll bar. Your result will look like the following:
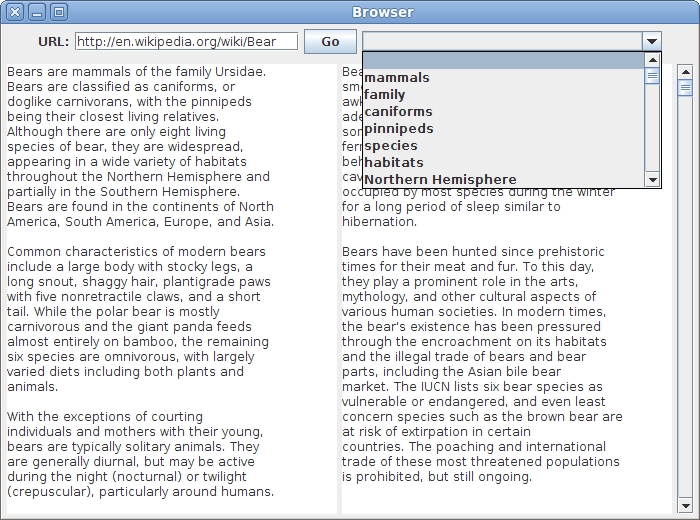
Only the text of the page will appear, with no attempt to render any markup except for paragraph boundaries. Hyperlinks in the page will not appear as clickable text but instead will be listed in a dropdown menu which the user can select from. When a page is loaded, the drop-down box on upper right part of the window will contain a list of all the parts of the text that are hyperlinked. When the user selects one from the drop-down box, then the page that it links to is loaded into the browser, in place of the current page.
Make a new directory for this project and copy the starter code from the course directory.
cp ~tvandrun/Public/cs245/proj6/* .
There are several big steps in this project, and you should work on these one at a time and confirm they work before you go on.
You are given two files, Browser.java and
PageModel.java.
The former contains all the code for the GUI, plus the main method
(it serves as both the "view" and the "controller").
The latter models the information of the currently loaded page.
Take a look at these files.
The visible window components are already set up for you in
Browser.
The work you will have to do in that class is to write
listeners for the button, dropdown menu,
and scroll bar.
The scroll bar requires a different kind of listener---not
an ActionListener but an
AdjustmentListener.
The PageModel class already has references
to certain parts of the GUI, but you will need to add instance
variables about the information needed to be stored and modeled.
I have also given stubs for methods that I suggest you write
for PageModel, but technically that is up to you:
Somehow the listeners are going to have to communicate
with the model, and you are free to define a different set of
method signatures than what I suggest.
Two of the method stubs are in fact private; I put them there to suggest helper methods---that is, to suggest how you might organize the steps in your code.
This will walk you through the required steps. Do these steps one at a time and test that they work as you go along.
Similar to what you saw in the in-class examples of the Fibonacci calculator and the Wikipedia searcher, the user will type text into the textfield and click the "Go" button. You will need to write an action listener to listen to the Go button and read from the textfield. At this point, simply print the the contents of the textfield to the terminal, to make sure you've done that correctly. Start thinking about what should and should not be on the EDT.
Next, modify your action listener so that instead of
printing the URL to the terminal, grab that contents of that URL
(you can imitate the code in the Wikipedia search example
for that and see the Java API for other details).
To confirm you are doing this correctly, dump the page source
to the terminal.
I recommend you do most of this work in the methods
loadURL() and processURI()
in class PageModel.
Since processURI() does not have any parameters,
this suggests that loadURL() would set an
instance variable.
You need to think about what would be appropriate instance variables
for a page model.
Make sure your interaction with the network is not being
done on the EDT.
Now modify your code so that instead of dumping the source
to the terminal, you form paragraphs from the text.
If you have never done any HTML before, talk to me and I'll give
you the five-minute version of everything you need to know
about HTML for this project.
You are responsible only for text contained in paragraphs
delimited by paragraph tags---so,
search for <p> and
</p>.
At this point ignore all other tags within paragraphs---that is,
ignore any other string begining with <
and ending with >.
I recommend that at this point you store the text so that each paragraph is one string and that the paragraph-strings are stored in an array list (ie, each position in the array list is one paragraph).
Now things get harder. Instead of dumping the text to the terminal, you need to display the text in the text areas. Each text area can support lines of up to 42 characters long and 29 lines each. This means you have to take the text you've grabbed from the webpage and
When I say "put the text in the pane" what I really mean
is make one big string for each pane (with appropriate line breaks)
and set that big string as the text for the text area.
I recommend you do most of the work for this in the
renderPage() method---of course, you need
to figure out when that method needs to be called... and
on what thread.
To make this easier, I recommend modifying your code that processed the text into paragraphs and stored each paragraph as a string in an array list so that instead each line (no more than 42 characters long) is its own string and stored separately in the array list.
Now for what is probably the hardest part. When the user clicks on the up or down arrows (a "unit increment"), you need to adjust both panes by one line (for example, if the user clicks the down arrow, then the top line of the left pane goes away, the other lines on the left side move up, the top line of the right pane moves the the bottom of the left pane, the other lines on the right pane move up, and a new line appears at the bottom of the right pane). For a "block increment", the text changes by an entire pane (eg, block decrement move the contents of the right pane to the left and grabs new content for the right pane).
What is really going on is that the page model needs to keep
track of the range of lines currently on what pane.
When the user adjusts the scroll bar, that change is reflected
in the page model.
Then renderPage() is called again, which
updates the two text areas.
Study the JScrollBar class in the Java API.
You're going to be using a new kind of listener with the scroll bar,
a AdjustmentListener.
This requires a method adjustmentValueChanged()
that takes a AdjustmentEvent object
as a parameter from which you can figure out what the user did
to the scroll bar ie
public YourClassToListenToTheScrollBar implements AdjustmentListener {
public void adjustmentValueChanged(AdjustmentEvent e) {
(Hint: I found the easiest thing to do was to set the scroll bar's maximum
value (JScrollBar.setMaximum()) to the
number of lines in the web page and for the model to have an instance
variable indicating the starting line of the left pane.
The getValue() method on
AdjustmentEvent will tell you where the scroll bar
is, from 0 to the set maximum.
Interpret that as the new starting line, and calcluate the
rest of the rendering from there.)
Let's take a look at how a hyperlink looks in a sample webpage.
<p><b>Bears</b> are <a href="/wiki/Mammal" title="Mammal">mammals</a> of the
We're interested in two things: the href (/wiki/Mammal)
and the text that is linked (mammals).
We're going to ignore the title.
(Arguably the title rather than the linked text is what we should
extract, but I would contend that the user is more likely
to notice the exact text as it appears on the page.)
So your first task is to modify your code that strips out the tags so that it handles anchor/href tags differently. Ultimately we will need to record the links and the texts, but first, test that you can extract them correctly by printing the links and texts to the screen while your program is processing the web page.
You may find that once you have the basic link-extraction working that you get some extra links that we would rather ignore---for example, links to anchor points within the current page. I suggest including an ad hoc test to weed out those links.
Once you are able to extract the links and linked texts,
find some way to store them so that they can be used later---specifically,
renderPage() will use them to modify the JComboBox.
My implementation uses two ArrayLists;
alternately a HashMap could be used.
Implement this, and test that it works by
moving the screen-dump of the texts and links to renderPage()
instead of the method where you strip out tags.
JComboBoxesStudy the API entry for JComboBox and
my use of it in the WikipediaSearch example.
In brief, it contains a set of Objects
(Strings, for our purposes) that it displays
in the drop down menu,
and it maintains a "currently selected item"---not only can the
user select an item, but it is also possible
to set a certain item to be "selected" with code.
There are two things we want to do with the JComboBox:
JComboBox.
clickLink() or something
equivalent.
Notice that most of the first point can be achieved using
the methods addItem()
and removeItemAt() or removeItem().
(There also is a method removeAll(),
but I couldn't get that to work correctly... I suspect there is a bug
in the version of the library we're using.)
The second point will involve putting an ActionListener
on the JComboBox which will react when the user
selects something.
You can then find out what was selected using
getSelectedItem() on the JComboBox.
One thing to be careful about:
Whenever you modify the JComboBox in code---such
as when removing or adding an item---you will trigger
an actionPerformed() on the ActionListener.
You need to find a way to distinguish between a user-initiated action and
one done in code.
I suggest a having an initial blank item in the menu,
setting the "selected item" to null while changing the menu,
or some combination of those.
Test to see that the right item is selected by printing
the selection to the terminal---say, in the method
clickLink().
Do this before trying to render the
right page (which is going to take more work...)
Now the final, hard part.
If the hyperlinks in the webpage were fully-formed
absolute URLs (such as http://en.wikipedia.org/wiki/Mammal),
then loading the next page wouldn't be so bad.
However, most webpages contain relative links
(/wiki/Mammal).
To load the correct page, you need to resolve the relative link to
an absolute link.
And here's the hint I'll give: look at the method
resolve() in class URI.
Then, load a new page, and make sure everything still works---for example, the links in the drop-down menu get reset. And then, you've written a working web browser!
Turn in your code by copying your directory (eg, proj6)
to a turn-in directory
I've made for you.
cp -r proj6 /cslab.all/ubuntu/cs245/turnin/(your user id)
DUE: Monday, Dec 3, 2012.