This lab has a variety of goals:
A Revision control system or version control system is a system for tracking changes to files and is an indespensible tool for working with a team on a shared software project.
Suppose two users are editing the same file, call it version A. Think of this as a source file for a software project, but it could be a document, a spreadsheet, an image, or anything.
User 1, after editing the file, saves it and thereby overwrites A to get A1. Suppose then user 2, who is still looking at and editing version A saves a new version (A2), killing user 1's changes.
To prevent something like this, we could implement some sort of locking mechanism, for example, user 1 locks file A until he is finished. However, then no work could be done in parallel, which a team might need to do. Also, a locking mechanism could easily be misused---what if user 1 locked a file and forgot to unlock it before going on vacation?
Moreover, some conflicts aren't merely at the file level. Suppose files A and B depend on each other---for example, suppose they are classes that call each other's methods. If they are edited separately but at the same time, the code would break because they each depend on the other's old version.
Finally, in addition to coordinating changes made by various team members, there is sometimes a need to bring back an old version of a file or group of files, or to branch the project into concurrent versions (for example, to experiment with two approaches for implementing a feature) and later to merge them together.
The solution to scenarios like this is a revision control system, software that tracks versions of shared files, keeping files and a log of changes in a repository.
Using a revision control system, user 1 and user 2 can each check out their own local copy of the file and edit it, commit their changes to the repository, and update their version from the repository.
In a future lab we will learn a widely-used revision control system and use it in future projects. In this lab you will implement a simple revision control system as an exercise to practice writing classes and linked structures.
Object-oriented design is concerned with the relationship among classes and other types--- which classes implement which interfaces, which classes serve as components to other classes (by means of instance variables), and (as we will learn about soon) which classes share code by inheritance or composition.
In a course like this we distinguish between teaching you "object-oriented programming" and "object-oriented design". On one hand we need to teach you the available features in a language like Java that involve classes and objects. On the other hand, you need to learn the wise and careful use of these features. The latter is the more difficult. In the first half of this course we will spend more time on "object-oriented programming", but we'll always keep object-oriented design in view as the motivation for the features.
Eclipse is an IDE (integrated development environment) that provides many helpful tools for programming in Java. Eclipse uses the concept of a "project" to organize code. In most labs you will start out by making a new Eclipse project for the thing you're working on.
JUnit is a system (built into Eclipse) for doing unit testing in Java. Unit testing is testing that code "units" (for example, methods or classes) satisfy requirements in specific test cases. Writing unit tests in JUnit is an important skill for serious Java programming, though it isn't covered head-on until CSCI 335 (Software Development). To get you used to the idea of unit testing, we are providing JUnit tests for this and many other labs.
Before lab starts I will give a brief demo on getting started in Eclipse and using the JUnit tests provided.
You will practice doing object-oriented design (and think about how revision control works) by designing your own simple revision control system. You will write a program that presents the user with a simple text area to edit. The user can "commit" changes made to the text area; these changes are saved in memory and assigned a version number; and the user can then go back to them later.
The user interface is a window that looks like this:

The "current" and "max" indicator at the top should display the version number of the currently displayed version (besides any changes that have been made since the last commit or recall) and the highest version number that has been assigned, respectively. When the program starts up, these should read "Current: 0" and "Max: 0", not "Current" and "Max" as the image shows.
When the user enters some text and then presses the "commit" button, the current and max counters should increment. Suppose the user then enters more text and presses "commit" again. If the user then presses the "<" button, the text should then revert to its state when the "commit" button was pressed the first time. Pressing the ">" button will change the text to what it was when "commit" was pressed the second time. In this way the user can shuffle though versions. Pressing "<" when the current indicator is 0 does nothing, and pressing ">" when the current indicator is equal to the max does nothing.
That specification would be adequate (and the problem very easy) if all the revisions were made in a linear fashion, and the user commited changes made only on the latest version-- in which case we would have an organization like
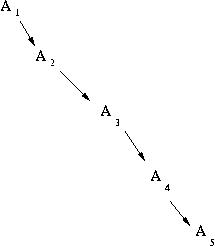
But what should happen if the user flips back to an earlier version, makes changes, and commits? Should the new version simply be put at the end of the chain, even though it does not descend from the latest version? Should the new version replace the version that used to come after the version that was edited, and the rest of the chain be lost?
Instead of the two options mentioned, your program should consider the series of versions to branch at this point. The new version will receive the next verions number (ie, the max version plus one), but instead of conceptually coming after the most recent version, it will be considered to branch off from the version it was derived from.
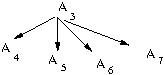
Suppose the user takes the collection of versions illustrated above, and then navigates back to version 3, makes a change, and commits (creating version 6). Then he or she makes another change (to the new version 6) and commits it as version 7. Then he or she navigates to 4, changes and commits, navigates back to 6 and makes to changes in a row, and navigates to version 5 to make and commit a final change. That would result in the following tree of versions.
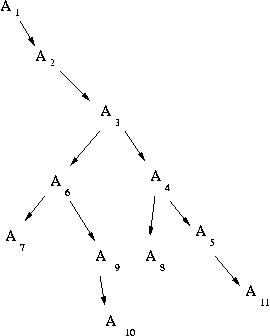
At this point, your version navigation feature should work as follows: When at version 6, pressing the "<" button will bring up version 3, the parent. Pressing ">" (at version 6) would bring up verion 9, the most recent decendant. To move among "sibling" versions, the user would use the "-" button; so, pressing the "-" button at version 6 would bring up version 4, and pressing "-" again would bring back version 6. If there are more than two siblings, the "-" should move around the sibling versions in a circular manner. (What order? We will arbitrarily choose that the "-" button will circulate from the oldest to the most recent. However, if the user presses the ">" button when viewing the parent of this group of siblings, the viewer will move to the most recent revision of the siblings. The diagra below shows a situation where versions 4, 5, 6, and 7 were all made from version 3. Being at 3 and pressing '>' will take one to the most recent version, 7. If the user then presses '-' several times, the current version will circulate 4, 7, 6, 5, 4, 7, 6, 5, 4 ...)