The goal of this project is to practice using pointers and dynamic memory in C. The specific object of this project--implementing a hashtable---also builds on what we have learned about abstract data types and their implementations.
This project will be similar to Project 3 (linked list implementation of a map in Java), the differences being that it will be in C and, generally, a little harder.
This project description has a fair amount of important stuff to read through. If you read better on paper than on a screen (most people do), don't be shy about printing this out and reading it all first. Paper is a sustainable, renewable, recyclable, and compostable resource. It's okay to use it. You are also strongly encouraged to review your code for Project 3.
Also, you are permitted to work with a partner on this, and turn in a single project between the two of you. But I encourage you to do this on your own if you are able to do so.
We have seen five abstract data types (ADTs): lists, maps, sets, stacks, and queues. We have also seen that each of these can be implemented using either a linked list or an array. In project 3, you implemented a map using a linked list.

Remember the advantages and disadvantages of arrays vs linked lists. Jumping to a position in an array is fast, O(1), because of random access, but inserting or removing things in an array is slow, O(n). Inserting or removing things in a linked list is fast, O(1) if you have already found the place to insert or remove, but finding something in a linked list is slow, O(n), because of sequential access.
Think about the operation of looking up a value for a key in a list using a linked list like what you did in project 3, where the nodes each contain a key and a value. One would need to step through the nodes in the linked list, checking each key until the right one is found. That's O(n).
O(n) might not seem so slow at first glace---after all, merge sort is O(n lg n) and selection sort and insertion sort are O(n^2). But keep in mind that map operations are not stand-alone algorithms but are operations that would be used in an algorithm. Thus if an O(n) operation happens inside a loop with O(n) iterations, the running time of the loop becomes O(n^2). For many purposes, that's just too slow.
What we want is an implementation of a map whose operations are constant time, O(1). To do this, we'll need to use an array so we can use random access. When we look up a value for a key, we want to be able to jump right to a position in the array.
But how can that be done?
If we kept all the keys in an array, we would still need to
search that array for the right key, and that would still be
O(n).
The trick is that since all information stored on a computer
can be broken down into numbers, and so we can
use the key to compute a number which we'll use as an
array index.
For example, if the keys in our map are strings, we can do
something like sum the ASCII codes of the characters in the string.
Generally, we need a (mathematical) function that maps
keys (such as strings) to numbers (that can be used as
array indices).
Such a function is called a hash function,
and an implementation of a map that uses a hash function to
look up a key's value in an array is called a hash table
or hash map,
This is where the name of Java's HashMap class
comes from.
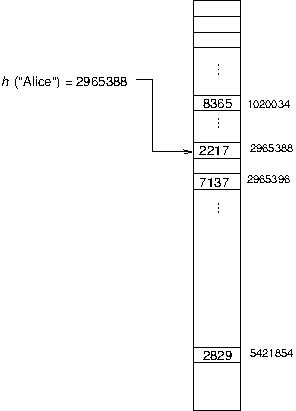
Problem: What if the hash for a key is beyond the bounds of the array? Or, stated another way: it seems like this would require a ginormous (as you kids would put it these days) array. What if we can't afford the space it would take to have an array big enough for all the indices that could be generated for the possible keys? This is no problem at all because with a smaller array we can simply mod (%) the hash by the length of the array, and it will wrap around to a valid array index. Once again, mod makes our life easier.
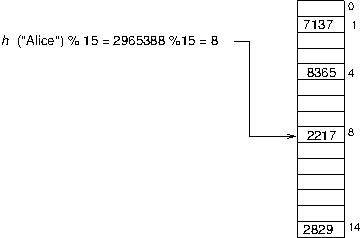
Problem: What if two keys hash to the same value---that is, what if the hash function assigns the same array index to more than one key? This is a serious problem; we'll refer to this as a collision. In our example above---using the "ASCII sum" of a string as a hash function---any two words that are anagrams of each other (all the same letters, just different order) will collide.
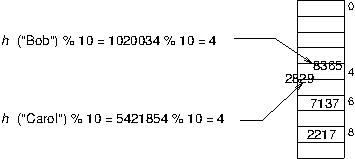
There are several ways to handle collisions. One of the simplest, which we will use here, is to use chaining. Instead of assuming an array that holds one value (or one key/value pair) in each position, we'll use an array of pointers to the head of little linked lists of key/value pairs; each linked list (called a bucket) is like the linked list you implemented in Project 3. This is called chaining because the key/value pairs that end up in the same bucket are chained together in the linkedlist.
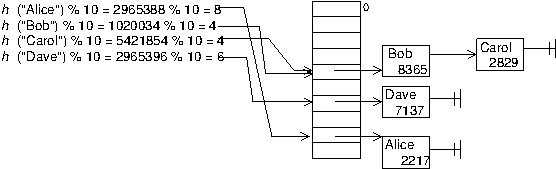
Thus any operation on the map will have two steps. Step 1: find the right bucket by computing the hash of the key, using the hash as an array index. Step 2: find the right node in the chain for that bucket.
Problem: What if all the keys---or even just a lot of them---get hashed to the same bucket? Wouldn't you have a very long chain to search through and we'd be back to O(n) time to look something up? Potentially, yes, that would ruin everything. The trick to avoid that situation is to make the array big enough and the hash function good enough to minimize collisions and prevent any chain from getting too long. It turns out the "ASCII sum" approach is not a very good hash function, but it will do for our purposes, since it's easy to implement.
(The mathy details: if the length of the array is proportional to n (the number of pairs stored) and if the hash function distributes the keys uniformly and independently over the range of array indices, then we can expect constant time for all the operations.)
If at some point the table becomes too full or any one chain becomes too long, then we can rehash the table: make a bigger array and redistribute the keys.
Your task is to implement a hashtable in C.
Copy starter code from the public folder for this project:
cp -r ~tvandrun/Public/cs245/proj6/* .
You will get the following files:
hashmap.h, a header file containing the struct for
the map itself (holding the array itself, the length, etc),
the struct for the nodes, and the prototypes for the operations.
hashmap.c, the implementation file, which is the
file you will work with.
driver.c, a program to test out the hashmap.
This is included mainly to help with your intuition by showing you
the hashmap in use.
You also can use it for hand-testing and debugging.
test.c, a program to do the "real" testing of
the hashmap, analogous to a JUnit testcase for a Java project.
makefile, a makefile for this project
Even though you won't be doing any coding in this phase or getting anything to work, it is very important to work through the code you're given carefully. If you don't understand what's going on in the code you're given, ask about it before you start on the next stuff. You may want to work through it with a friend, like you would in lab, even if you do the rest of the project separately.
First look at hashmap.h and driver.c
to consider the interface of the hashmap and how it is
used by the driver.
The structs are documented carefully, make sure you understand
them thoroughly.
One thing to notice in particular is the prototype for the
function keys().
This function allocates and returns an array containing all of
the keys in the hashmap.
This is analogous to an iterator of the keyset in
Java's HashMap class.
But since C doesn't have iterators, we instead pass an array
of keys.
Now, in hashmap.c, consider the first
four functions, already complete.
The function hash() takes a string and the
number of buckets and computes a hash for that string using
the "ASCII sum" approach described earlier.
The function create() takes a size for
the array (or, number of buckets), and allocates the parts of
this map.
Make sure you understand why and how we are allocating both a hash
map and an array of nodes, but no actual nodes.
(The bucketSizes array, which is another field of
the hashmap, will be used by the monitor() function.)
The function getNode() is like the method of the same
name you wrote in Project 3---it's a helper function
that finds a node, given a key.
This is more complicated that the one in Project 3, though,
because we first need to find the right bucket (using hash()),
and then search that bucket.
Note how strcmp is used to determine whether
the key of the current node matches the key we're looking for.
Finally, containsKey()
uses getNode().
It determines whether or not there exists an association for a given key.
You can run the driver program by making and running:
make driver ./driver
...but it doesn't work because you haven't written the hash map yet. (But it does compile and doesn't crash.) You can also compile and run the test program:
make test ./test
The first test, empty containsKey, works out of the box.
The others fail.
As you do the phases of this project, make sure earlier tests
that were working don't fail, and at no point should
your project crash with a segmentation fault.
put() functionYour turn.
Implement put().
If a node for the given key already exists, find it
and replace the value.
Otherwise, allocate (using malloc)
and set the variables for a new node,
and but the node in the appropriate bucket.
As usual for a linked list, the easiest place to add is at the head.
Also make sure the number of keys is updated.
If you were doing this in Java, it would look something like this:
Node oldAssoc = getNode(key);
if (oldAssoc != null)
oldAssoc.value = val;
else
buckets[hash(key)] = new Node(key, val, buckets[hash(key)]);
Where the line
buckets[hash(key)] = new Node(key, val, buckets[hash(key)]);
should remind you of lines like head = new Node(item, head);.
Of course, you're not writing in Java, so you will have to "translate"
all this to C.
If you do this correctly, the second test,
put containsKey, will work.
get() functionThe next function, get() is much easier.
Again you can use getNode().
If there is no such association for the given key,
this should return NULL.
If you do this correctly, the tests through #4 should work,
the new ones being put get and put replace.
But note that these also exercise further your code for
put();
if these new tests fail, it might be a problem from the previous step.
keys() functionNow write a function that will
allocate (with calloc) an array to hold strings
(note the return type
is char**---pointer to pointer to char, that is,
array of pointers to (beginnings of) arrays of chars);
populate it with the keys, and return it.
This will mean looping through the array of buckets and, for each
bucket, looping through all the nodes.
Note it is the responsibility of the code calling this function
to deallocate the array.
You can see that deallocation in driver.c, for example.
When this is done, the tests through 5, populated keys,
should work.
destroy() functionNow write a function that will undo everything done in
create()
This function must deallocate all the parts of the hashmap
(the individual nodes and the bucket array) as well as the
map itself.
But do not deallocate they keys and values--these are pointers
to strings that are allocated statically.
No new tests will pass, but run the tests and make sure none of them crash.
Finally, complete one of the following three tasks. For extra credit, complete two or all of them.
remove() functionRemove the association for a given key.
You can't use getNode() for this one because
you need to find the node that comes before the node
containing the key you're looking for.
Instead you need to find the bucket where the key is (or would be),
and remove the node from that bucket.
You'll need to handle the special case where the node you want to
remove is the head of the chain in that bucket, and otherwise loop
through the list, always looking one step ahead.
Again you may want to refer to your code from Project 3.
Don't forget to use strcmp() to compare keys.
removeKey() should remove the value of association
being removed, or NULL if the key doesn't exist.
It should also deallocate the node being removed
(but not the key or value).
Tests 6 and 7 (empty remove and populated remove)
will test that this is done correctly.
rehash() functionWrite a function that will make a bigger array to replace the current buckets array, and redistribute the keys into that new buckets array.
Here's how I recommend doing it:
Make a new map using create(),
giving it an initial size larger than the current size.
(How much larger? That's up to you.)
Then iterate through all the keys
(getting the keys from keys()),
adding each key and value to the new map (using put()
and get()).
Finally, perform "transplant surgery", making the new
map's bucket array and other guts to be the new guts of the
old map.
Deallocate everything that's not in use any more---especially the
old map's old bucket array and the new map itself.
But don't call destroy() on the new map, since
that will also deallocate the new map's bucket array, which
now belongs to the old map...
The 8th test, populated rehash, will test this.
monitor() functionWrite the function monitor() that
will print out to the screen the number of items in each
bucket and the maximum number of items in any bucket.
This could be used to monitor how will the items are distributed
among the buckets.
You'll notice that the hashmap struct has
an array called bucketSizes that can be used
to keep track of the number of items in each bucket.
Revise the functions put() and removeKey()
so that this array is kept current as the hashmap changes.
Then it is a simple loop in monitor() to print out
the sizes of these buckets as recorded in bucketSizes.
Test 9, populated monitor should have output
something like this:
9. Populated monitor 0: 2 1: 4 2: 3 3: 1 4: 6 max: 6
It won't indicate pass or fail explicitly.
Copy the completed hashmap.c
file
to the turn-in folder for this project:
cp (some file) /cslab.all/ubuntu/cs245/turnin/(your user id)/proj6
DUE: 5:00 pm Monday, Apr 6, 2015. Note that this overlaps with projects 5 and 7.