This lab provides an introduction to using Mercurial for revision
control along with using arrays in Java. Read this carefully so that
you have a chance to think about the first problem before you come to
lab.
Note that you do need to indicate that you
have done the reading by visiting the online version of this page at
http://cs.wheaton.edu/~cgray/csci235/labs/prelab-arrays.php.
Read through the introduction to Mercurial, but don't miss overlook the problem description near the end that you should think about before coming to class.
Mercurial is a revision control system. That means it is designed to help track work on a collection of files, giving you the ability to identify and retrieve the revisions that existed at various points during the process. The huge motivation for revision control is when there are several people all working on the same program (or collection of programs), because then it is very helpful to be able to fugure out what was changed and by whom. But revision control is also helpful when you are working by yourself: if you manage to make a mess, you can back up to a coherent prior state.
Mercurial can do much more than we need in this class. If you get really interested, or you need something more, there is a very good online tutorial and reference, This page is limited to the features you are most likely to need in this class.
Mercurial manages a subtree of files: a directory and all of its
subdirectories. This matches the way we usually work on projects
(including labs): we make a new directory for each new project. When
we are working in a Mercurial-managed tree, we see the files there as
we would normally. But Mercurial also maintains, behind the scenes,
additional files that keep the history and other information; we call
that hidden collection the repository. (The repository is
actually hiding in a dirctory named .hg, taking advantage
of the fact that names beginning with dot are not normally shown.) The visible
files we actually work with are called a working copy. We
manage the repository and its relationship with the working copy using
the hg commmand.
The main Mercurial command hg is always followed by
another command that tells Mercurial what to do. It is very helpful
to remember that one of those commands is help. So you
can always do
$ hg helpto get general help, or add a command, such as
update, to
the end of the help to get a reminder of what that command does and
what its arguments can be; for example,
$ hg help updateor even
$ hg help help
Before you can make very much use of Mercurial, you need to do a
tiny bit of setting up (which has already been done for the lab
accounts, and in rudimentary form for the accounts of students in this
class). Whenever you run hg, it will look for a file
named .hgrc in your home directory for some settings and
options. You can add to that later on if you want to set some more options.
In this class, you'll often start from a repository that already exists; you'll create your own working copy and repository by cloning the existing repository. When that repository is local, you can name it with its filename; so the command
$ hg clone /cslab/class/csci235/in-class/09-10 .will clone the repository under
/cslab/class/csci235/in-class/09-10
to the current working directory (that's the dot); it will make a new
directory named 09-10 to hold the working copy and repository.
See the notes online for instructions about how to create a new repository in a directory that you already have.
hg summary
Show what revision the working copy is based on.
hg status
Show the status of files in the working copy. The status letters you'll see most often are
? this file is not known to the repository (and not ignored)
! this file is in the repository, but missing
from the working copy
M the working copy has been modified since the
last commit
A the file has been added to the repository, but
not yet committed
hg add filenames
Add the files to the set that are tracked by the repository.
hg remove filenames
Remove the files from both the working copy and the repository.
hg forget filenames
No longer track these files.
hg log filenames
Show the history of commits to the named files.
hg update
Update the working copy to match the repository.
hg commit -m "message"
Commit the changes in the working copy to the repository. Replace message with a brief description of what has changed; this is the information that will be shown by the log command.
The general pattern you will use most of the time is
hg clone
hg add to tell the
repository about it. If you want to get rid of a file,
use hg remove to remove it from the working copy and
tell the repository that it goes away. Or, if you just want it to
go away in the repository, use hg forget.
hg status to check whether you've missed
anything (and use add or forget as
needed).
hg commit to add a snapshot of the working
copy to the repository.
You can also pick a particular revision from those that appear in the log, copy or rename files, and revert one or more files in the working copy to a version from the repository. See the online documentation (and future labs) for more information about that.
Mercurial is designed to make it easier to work with multiple copies of a repository--either for more than one person working on it or for one person working in more than one place. Those things will often require merging revisions, which is another topic for later.
There are special ways to copy a directory with a Mercurial repository. If you are making a new copy, it is called cloning; there are other commands for making two existing copies match.
A repository can be local, in which case you name it specifying the name of the directory where it exists; that is what the example clone command above does.
When a repository is remote, you need to tell how to reach
it, which you can do with a URL using ssh. If the other computer is
named cslab25 and the account name there is
mortimer.snerd, the URL will have the form
ssh://mortimer.snerd@cslab25/directory-path (see
the example below).
If user mortimer.snerd wants to create a new copy of
the repository in the current directory (in a lab account) as the directory
csci235/lab4 under his home directory, the command would be
$ hg clone . ssh://mortimer.snerd@cslab25/csci235/lab4The dot is the source (here), and the URL is the remote name.
He'll be prompted for his password, twice.
When he logs in to his own account and changes into the
csci235/lab4 directory, all that will be there is the
repository--no working copy. To set up the working copy, he would
need to
$ hg updatewhich makes the working copy match the last committed version from the repository.
When another copy of a repository already exists, you push local changes to the remote copy, and you pull remote changes to the local copy. Usually you want to check what will happen before you do it.
To push changes out, our friend Mortimer would first
$ hg outgoing ssh://mortimer.snerd@cslab25/csci235/lab4to see what changes need to go, then
$ hg push ssh://mortimer.snerd@cslab25/csci235/lab4to transfer them.
To pull changes in, the sequence would be
$ hg incoming ssh://mortimer.snerd@cslab25/csci235/lab4to check, then
$ hg pull ssh://mortimer.snerd@cslab25/csci235/lab4to transfer the changes.
If you are doing this to move files to and from your own computer, you'll probably want to run the push and pull commands on your computer, because the lab computers are easier to name.
The Sieve of Eratosthenes is a method for finding prime numbers. The idea is first to write out all numbers (from 2 up to a certain highest number) in a list.
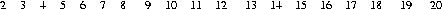
Then cross off all the multiples of 2.
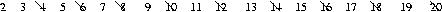
The next uncrossed number (in this case 3) is also the next prime number. Cross off every 3rd number that's not already crossed off.
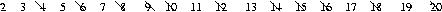
Repeat this process. Find the next uncrossed number (say, n) and cross off every nth number after that.
Your task will be to write a program that uses this technique to compute all the prime numbers less than 100.
Things to think about: